Apache Flink takes center stage in the world of stream processing frameworks, offering unique features and capabilities that set it apart. Dive into this comprehensive guide to uncover the inner workings of Apache Flink and how it revolutionizes data processing.
Overview of Apache Flink

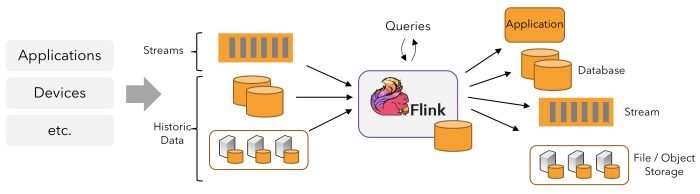
Apache Flink is an open-source stream processing framework that provides efficient and reliable processing of large-scale data streams. It is designed to handle real-time analytics, event-driven applications, and batch processing with high throughput and low latency.
Key Features of Apache Flink
- Fault Tolerance: Apache Flink ensures fault tolerance through its distributed snapshot mechanism, allowing for consistent and reliable processing of data streams.
- Low Latency: With its stream processing engine, Flink can process data with low latency, making it suitable for real-time applications.
- Exactly-Once Semantics: Flink guarantees exactly-once semantics for stateful operations, ensuring accurate results without duplication or loss of data.
- Rich APIs: Apache Flink provides APIs in Java, Scala, and Python, making it accessible to a wide range of developers.
Architecture of Apache Flink
Apache Flink follows a pipelined data processing architecture, where data streams are processed in parallel across a cluster of nodes. The key components of Flink’s architecture include:
JobManager: Manages the execution of jobs and coordinates the distribution of tasks across TaskManagers.
TaskManager: Executes the tasks assigned by the JobManager and manages the data processing within its assigned slots.
State Backend: Stores the state of the streaming applications and allows for fault tolerance and recovery in case of failures.
Checkpointing: Flink uses checkpointing to take consistent snapshots of the application state, ensuring fault tolerance and data consistency.
Apache Flink Ecosystem
Apache Flink has a robust ecosystem that includes various components to support different aspects of big data processing. Let’s delve into some of the key components and explore how Apache Flink compares to other popular frameworks like Apache Spark.
Components of the Apache Flink Ecosystem
- Apache Flink Core: The core of Apache Flink provides the necessary APIs and libraries for data processing and analytics.
- Apache Flink Streaming: This component focuses on real-time data processing, allowing for continuous data streams to be processed efficiently.
- Apache Flink Batch: For batch processing, Apache Flink Batch enables the processing of large volumes of data in a distributed manner.
- Apache Flink Gelly: Gelly is a graph processing API that allows for the efficient processing of graph data structures.
- Apache Flink ML: This component provides machine learning libraries and tools for implementing advanced analytics and predictive models.
Comparison with Apache Spark
- Apache Flink vs. Apache Spark: While both frameworks excel in processing large-scale data, Apache Flink is known for its superior performance in real-time processing due to its optimized streaming capabilities.
- Apache Flink’s support for event time processing and state management sets it apart from Apache Spark, making it a preferred choice for complex event processing and low-latency applications.
- On the other hand, Apache Spark is widely used for batch processing and interactive analytics, offering a more mature ecosystem and broader adoption in the industry.
Role of Apache Flink in Real-Time Analytics and Batch Processing
Apache Flink plays a crucial role in enabling organizations to perform real-time analytics and batch processing efficiently. Its ability to process data streams with low latency and high throughput makes it ideal for applications requiring real-time insights. Additionally, Apache Flink’s support for fault tolerance and scalability ensures reliable processing of large volumes of data in batch mode. Overall, Apache Flink’s versatility in handling both real-time and batch workloads makes it a valuable tool for a wide range of big data processing use cases.
Apache Flink APIs

Apache Flink provides several APIs that cater to different data processing needs. Each API has its own set of benefits and limitations, making it essential for users to choose the right one based on their requirements.
DataStream API
The DataStream API in Apache Flink is designed for processing continuous streams of data. It allows users to perform operations like filtering, mapping, aggregating, and windowing on real-time data streams. Below is an example of how the DataStream API can be used to calculate the sum of integers in a stream:
“`java
DataStream stream = env.fromElements(1, 2, 3, 4, 5);
DataStream sum = stream.reduce((value1, value2) -> value1 + value2);
sum.print();
env.execute();
“`
Benefits:
– Ideal for processing real-time data streams.
– Supports event time processing.
– Enables efficient windowing operations for time-based aggregations.
Limitations:
– May not be suitable for batch processing tasks.
– Requires handling of state and checkpointing for fault tolerance.
DataSet API
The DataSet API in Apache Flink is used for processing batch data sets. It allows users to perform transformations like filtering, grouping, joining, and sorting on static data sets. Here is an example of how the DataSet API can be used to find the maximum value in a dataset:
“`java
DataSet dataSet = env.fromElements(1, 5, 3, 2, 4);
DataSet max = dataSet.max(0);
max.print();
env.execute();
“`
Benefits:
– Suitable for batch processing of static data sets.
– Provides optimizations for batch operations.
– Supports iterative processing for machine learning algorithms.
Limitations:
– Not suitable for real-time streaming data.
– May not be as efficient for processing large volumes of data compared to the DataStream API.
Table API
The Table API in Apache Flink offers a relational API for processing structured data. It allows users to write SQL-like queries on data streams and datasets. Below is an example of how the Table API can be used to select records from a table:
“`java
Table table = tableEnv.fromDataSet(dataSet, “value”);
Table result = tableEnv.sqlQuery(“SELECT * FROM table WHERE value > 2”);
DataSet resultSet = tableEnv.toDataSet(result, Row.class);
resultSet.print();
“`
Benefits:
– Simplifies complex data transformations through SQL-like queries.
– Supports both batch and streaming data processing.
– Provides a familiar interface for users familiar with SQL.
Limitations:
– Limited support for advanced analytics functions compared to other APIs.
– May require additional setup for integrating with existing systems.
SQL API
Apache Flink also offers a SQL API that allows users to write SQL queries directly on data streams and datasets. It provides a familiar interface for users comfortable with SQL syntax. Here is an example of how the SQL API can be used to filter records from a stream:
“`java
tableEnv.registerDataStream(“myTable”, stream, “value”);
Table result = tableEnv.sqlQuery(“SELECT * FROM myTable WHERE value > 3”);
DataStream resultSet = tableEnv.toAppendStream(result, Row.class);
resultSet.print();
env.execute();
“`
Benefits:
– Enables users to leverage existing SQL skills for data processing.
– Supports both batch and streaming data processing.
– Provides optimizations for SQL queries to improve performance.
Limitations:
– Limited support for complex data processing compared to other APIs.
– May require additional configuration for integrating external data sources.
Apache Flink Use Cases
![]()
Apache Flink is utilized across various industries for stream processing, event-driven applications, and real-time analytics. Its ability to handle large volumes of data with low latency makes it a popular choice for organizations looking to harness the power of real-time data processing. Let’s delve into some key industry use cases and explore how Apache Flink is leveraged for different applications.
Financial Services
- Real-time fraud detection: Apache Flink is used to process incoming transaction data in real-time, enabling financial institutions to detect and prevent fraudulent activities as they occur.
- Algorithmic trading: Flink’s stream processing capabilities allow financial firms to analyze market data and execute trades at high speeds, optimizing trading strategies for better returns.
E-commerce
- Personalized recommendations: Apache Flink helps e-commerce platforms analyze user behavior in real-time to deliver personalized product recommendations, enhancing the shopping experience and increasing sales.
- Inventory management: By processing real-time data on inventory levels and customer demand, e-commerce companies can optimize stock levels and reduce out-of-stock situations, improving customer satisfaction.
Telecommunications
- Network monitoring: Apache Flink is used for real-time analysis of network data to detect anomalies, optimize network performance, and ensure seamless connectivity for customers.
- Customer churn prediction: By analyzing customer behavior data in real-time, telecommunications companies can predict and prevent customer churn, leading to better customer retention rates.
Healthcare
- Real-time patient monitoring: Flink enables healthcare providers to monitor patient data in real-time, allowing for timely interventions and improved patient outcomes.
- Disease outbreak detection: By processing large volumes of healthcare data in real-time, Apache Flink helps in early detection of disease outbreaks and enables swift response measures to control the spread.
In conclusion, Apache Flink stands out as a powerful tool for real-time analytics and batch processing, with a versatile ecosystem and robust APIs. Embrace the possibilities that Apache Flink offers and elevate your data processing capabilities to new heights.
When it comes to efficient and scalable data storage, many companies turn to MongoDB storage. With its flexible document-oriented structure, MongoDB offers a reliable solution for handling large volumes of data while ensuring high performance.
For businesses that require uninterrupted access to their data, implementing high availability data storage is crucial. By utilizing redundancy and failover mechanisms, organizations can minimize downtime and ensure data integrity even in the face of hardware failures.
Managing vast amounts of data efficiently is a challenge that many enterprises face, which is why Cassandra data management has become increasingly popular. With its distributed architecture and decentralized nature, Cassandra offers a robust solution for handling massive data sets across multiple servers.



{kind=link}