Starting off with Data partitioning techniques, this introductory paragraph aims to grab the readers’ attention and provide a glimpse into the world of efficient data management through strategic partitioning methods. From defining the techniques to exploring their implementation and performance benefits, this topic delves into the core principles of data partitioning for optimal data handling.
Exploring the nuances of horizontal and vertical partitioning, comparing range and hash partitioning, and delving into real-world applications, this discussion offers a comprehensive overview of how data partitioning techniques play a crucial role in modern data management strategies.
Overview of Data Partitioning Techniques
Data partitioning techniques involve dividing a dataset into smaller, more manageable parts to improve data processing efficiency and scalability. By partitioning data, organizations can distribute workloads, enhance performance, and optimize resource utilization across different systems or nodes.
Importance of Data Partitioning in Data Management
Data partitioning plays a crucial role in data management by facilitating parallel processing, reducing bottlenecks, and ensuring high availability and fault tolerance. It allows for better utilization of hardware resources and enables systems to handle large volumes of data more effectively.
- Improved Performance: Data partitioning helps distribute query processing and data retrieval tasks across multiple nodes or servers, reducing the load on individual components and improving overall system performance.
- Scalability: By partitioning data, organizations can easily scale their systems horizontally by adding more nodes or servers as the dataset grows, ensuring that performance remains consistent.
- Fault Tolerance: Partitioning data enables systems to replicate and distribute data across multiple nodes, reducing the risk of data loss in case of hardware failures or system crashes.
Examples of Industries or Applications where Data Partitioning is Crucial, Data partitioning techniques
Data partitioning is essential in various industries and applications where handling large volumes of data efficiently is paramount. Some examples include:
- E-commerce Platforms: Online retailers often use data partitioning to manage product catalogs, customer information, and transaction data effectively to ensure fast and reliable service.
- Financial Services: Banks and financial institutions partition data to analyze customer transactions, detect fraudulent activities, and comply with regulatory requirements while maintaining data integrity and security.
- Healthcare: Healthcare providers leverage data partitioning to store and process patient health records, medical imaging data, and research findings securely while ensuring quick access to critical information.
Types of Data Partitioning Techniques

Horizontal partitioning involves dividing a table into multiple smaller tables, each containing a subset of rows. This technique is beneficial for distributing data across multiple servers to improve query performance and scalability.
Vertical partitioning, on the other hand, entails splitting a table into multiple smaller tables, each containing a subset of columns. This approach can be advantageous for reducing storage requirements and improving data retrieval efficiency by only accessing the necessary columns.
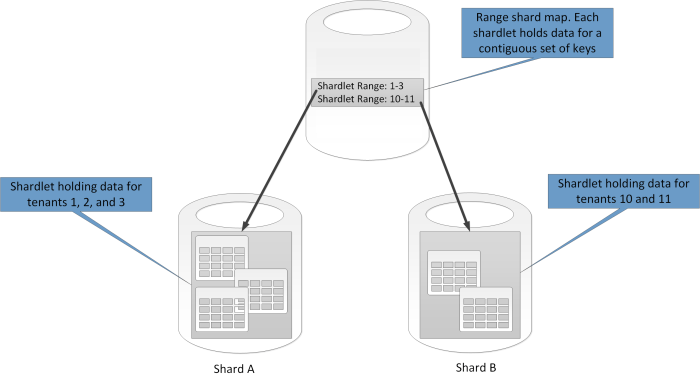
Range Partitioning vs. Hash Partitioning
Range partitioning involves dividing data based on a specified range of values, such as dates or numerical ranges. This method is useful for organizing data that naturally falls into distinct ranges, allowing for easier data management and efficient querying.
Hash partitioning involves distributing data across partitions using a hash function to determine the partition for each record. This technique is beneficial for achieving a more even distribution of data and can improve performance by spreading the workload evenly across partitions.
Implementation of Data Partitioning: Data Partitioning Techniques

Implementing data partitioning involves several common strategies to ensure the efficient distribution of data across different partitions. One key step is to carefully choose the right partitioning technique based on the specific characteristics and requirements of the dataset. Let’s explore some common strategies for implementing data partitioning and discuss how to choose the appropriate technique for different scenarios.
Choosing the Right Partitioning Technique
When selecting a partitioning technique for a specific dataset, it is essential to consider factors such as data distribution, query patterns, and scalability requirements. For example, if the dataset is highly skewed with certain keys having significantly more data than others, a hash-based partitioning technique may be more suitable to evenly distribute the workload. On the other hand, if range queries are frequent and require accessing contiguous data, range partitioning may be more appropriate. Understanding the nature of the data and the access patterns is crucial in determining the most effective partitioning strategy.
- Hash Partitioning: Ideal for evenly distributing data across partitions, especially when data distribution is skewed.
- Range Partitioning: Suitable for scenarios where range queries are common and require accessing contiguous data.
- List Partitioning: Useful when data needs to be grouped based on specific criteria or categories.
Scenarios for Different Partitioning Techniques
Depending on the specific requirements of the dataset and the application, different partitioning techniques may be more suitable for optimal performance. For instance, in a social media platform where user data is stored, hash partitioning can help evenly distribute user profiles across partitions to ensure balanced query processing. On the other hand, in a financial system where transactions are recorded based on time intervals, range partitioning based on transaction timestamps can facilitate efficient data retrieval for time-based queries. By analyzing the characteristics of the dataset and the access patterns, organizations can determine the most effective partitioning technique to enhance performance and scalability.
Performance and Scalability Considerations

Data partitioning plays a crucial role in enhancing system performance and addressing scalability challenges. By distributing data across multiple nodes or servers, data partitioning helps improve query response times, reduce network traffic, and increase overall system efficiency.
Enhanced System Performance
- Reduces query response times: Data partitioning allows queries to be executed in parallel across multiple partitions, leading to faster response times.
- Minimizes network traffic: By storing relevant data closer to where it is needed, data partitioning reduces the amount of data transferred over the network, improving performance.
- Optimizes resource utilization: Partitioning data can help balance the workload across servers, preventing bottlenecks and ensuring efficient resource utilization.
Scalability Challenges and Solutions
- Scalability challenges: As data volumes grow, traditional systems may struggle to handle increased workload and data processing demands.
- Data partitioning for scalability: By partitioning data, organizations can scale their systems horizontally, adding more nodes or servers to accommodate growing data volumes and user requests.
- Elastic scalability: Data partitioning allows systems to scale elastically, adding or removing nodes dynamically based on workload requirements.
Real-World Examples
- Google Bigtable: Google’s Bigtable database uses data partitioning to improve performance and scalability for storing massive amounts of data across distributed systems.
- Amazon DynamoDB: DynamoDB partitions data to ensure high availability and scalability for applications with varying workload demands, providing consistent performance.
- Facebook’s Cassandra: Cassandra partitions data to handle large amounts of user data and provide seamless scalability for Facebook’s social networking platform.
In conclusion, Data partitioning techniques are essential for enhancing system performance, overcoming scalability challenges, and ensuring efficient data management across various industries and applications. By choosing the right partitioning technique and implementing it effectively, organizations can unlock the full potential of their data resources and drive business success in a data-driven world.
When it comes to managing large amounts of data, businesses need a solution that can handle their growing storage needs. This is where scalable data storage comes into play. By utilizing scalable storage systems, companies can easily expand their storage capacity as needed without experiencing downtime or performance issues.
One popular solution for scalable data storage is the Hadoop Distributed File System (HDFS). HDFS is designed to store and manage large amounts of data across a distributed network of servers, making it an ideal choice for organizations with massive datasets. By using HDFS, businesses can ensure data reliability, availability, and scalability.
Another key concept in the world of data storage is distributed data storage. This approach involves spreading data across multiple servers or locations, providing redundancy and fault tolerance. Distributed data storage systems are highly scalable and can handle massive amounts of data, making them essential for modern businesses dealing with big data.



{kind=link}