ETL vs ELT in Big Data sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail with ahrefs author style and brimming with originality from the outset.
In the realm of Big Data processing, the choice between ETL and ELT methodologies can significantly impact the efficiency and scalability of data pipelines. Let’s dive deeper into the nuances of these processes to understand their implications in the digital landscape.
ETL vs ELT Overview

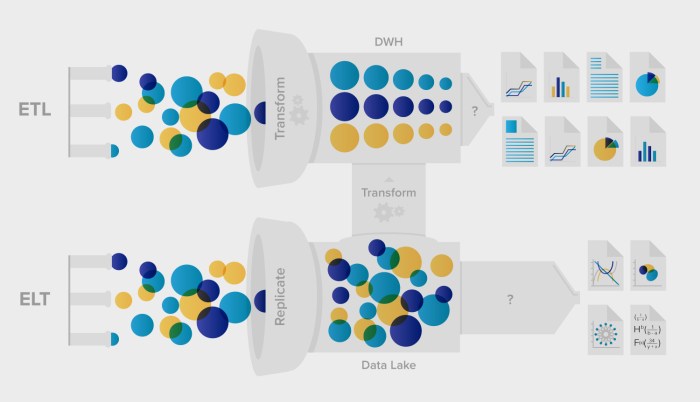
When it comes to handling Big Data, ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two common processes used for data integration and analysis.
Transitioning to cloud-native data management offers organizations the flexibility and scalability needed to thrive in the digital age. By leveraging cloud technologies, businesses can streamline operations and access their data from anywhere in the world.
ETL involves extracting data from various sources, transforming it into a suitable format, and then loading it into a data warehouse for analysis. On the other hand, ELT focuses on extracting raw data, loading it into a storage system, and then transforming it as needed for analysis.
Fundamental Differences
- ETL: Data is extracted, transformed, and then loaded into a data warehouse. This process is suitable for traditional data warehouses where transformation needs to happen before loading.
- ELT: Data is extracted and loaded into a storage system first, and then transformations are applied as needed. This process is beneficial for modern data warehouses that can handle raw data and perform transformations on the fly.
Data Flow in ETL and ELT
In an ETL pipeline, data is first extracted from source systems, then transformed using various rules and functions, and finally loaded into a data warehouse for analysis. This sequential process ensures that data is cleaned and structured before analysis.
Real-time data processing is essential for businesses that rely on up-to-the-minute insights to make critical decisions. With the ability to analyze and act on data as it is generated, companies can gain a competitive edge in today’s fast-paced market.
On the other hand, in an ELT pipeline, data is extracted from source systems and loaded into a storage system without immediate transformation. Transformations are applied later, as needed, to analyze the data efficiently. This allows for more flexibility and scalability in handling large volumes of raw data.
When it comes to managing large amounts of data, database clustering is a crucial technique that ensures high availability and scalability. By distributing data across multiple servers, organizations can achieve better performance and fault tolerance.
ETL Process Deep Dive

The Extract, Transform, Load (ETL) process plays a crucial role in Big Data processing by retrieving data from various sources, transforming it into a usable format, and loading it into a target destination for analysis.
Advantages of ETL in Data Processing
- ETL allows for data consolidation from multiple sources, enabling a comprehensive view for analysis.
- It helps in cleaning and standardizing data, ensuring data quality and consistency.
- ETL processes can be automated, improving efficiency and reducing manual errors.
- It enables historical data integration, facilitating trend analysis and forecasting.
Disadvantages of ETL in Data Processing, ETL vs ELT in Big Data
- ETL processes can be time-consuming, especially when dealing with large volumes of data.
- Data latency may occur during the ETL process, leading to delays in data availability for analysis.
- Changes in source data structures may require frequent ETL pipeline modifications, impacting scalability.
- ETL processes involve data movement, which can pose security risks if not adequately managed.
Commonly Used Tools for ETL in Big Data
- Apache NiFi: A powerful data ingestion and distribution system with a user-friendly interface.
- Talend Open Studio: An open-source ETL tool offering a wide range of data integration capabilities.
- Informatica PowerCenter: A popular ETL tool known for its scalability and performance in handling large datasets.
- Microsoft SQL Server Integration Services (SSIS): A comprehensive ETL tool for managing data workflows in SQL Server environments.
ELT Process Deep Dive

When it comes to Big Data processing, the Extract, Load, Transform (ELT) process plays a crucial role in managing and analyzing large volumes of data efficiently. Unlike the traditional ETL approach, ELT involves loading the raw data into a data warehouse or repository first, and then performing the transformation processes directly on the data within the storage environment.
This approach offers several advantages, such as leveraging the processing power of the storage system for transformations, eliminating the need for an intermediary staging area, and enabling real-time data processing and analysis.
Scalability and Performance Comparison
- Scalability: ELT is highly scalable as it allows for processing large volumes of data without the need for complex ETL pipelines. The ability to perform transformations directly within the storage environment enhances scalability by utilizing the resources available.
- Performance: ELT typically offers improved performance compared to ETL, especially when dealing with massive datasets. By leveraging the processing capabilities of the storage system, ELT can execute transformations more efficiently and quickly.
Suitability of ELT for Big Data Processing
- Real-time Analytics: ELT is well-suited for scenarios that require real-time data processing and analytics. By processing data directly within the storage environment, ELT enables faster insights and decision-making.
- Complex Transformations: When dealing with complex data transformations that involve large datasets, ELT can be more efficient than ETL. The ability to leverage the storage system’s processing power can speed up the transformation processes.
- Cost Efficiency: ELT can be more cost-effective in certain situations, as it eliminates the need for additional hardware or software for staging areas in ETL pipelines. This can result in cost savings for organizations dealing with Big Data processing.
ETL vs ELT Performance Analysis: ETL Vs ELT In Big Data
When comparing the performance of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) approaches in Big Data projects, several factors come into play that affect data processing speed and efficiency.
Impact on Data Processing Speed
- ETL: In the traditional ETL approach, data is first extracted from the source systems, then transformed according to the predefined rules, and finally loaded into the target data warehouse. This sequential process can often lead to longer processing times, especially when dealing with large volumes of data.
- ELT: On the other hand, ELT processes data as it is extracted, loading it into the target system first and then performing transformations. This parallel processing can significantly improve data processing speed, as there is no need to wait for the entire dataset to be transformed before loading.
Efficiency Comparison
- ETL: While ETL provides a structured approach to data processing, the need to transform data before loading it can sometimes lead to inefficiencies, especially when dealing with complex transformations or frequent data updates.
- ELT: ELT, with its load-first approach, allows for greater flexibility in handling diverse data types and formats, as well as the ability to leverage the processing power of the target system for transformations, leading to improved efficiency in certain scenarios.
Real-World Examples
One real-world example showcasing the performance metrics of ETL vs ELT in Big Data projects is a retail company processing sales data. In this scenario, the company implemented ELT for loading raw sales data directly into a cloud-based data lake, allowing for faster data ingestion and analysis compared to the traditional ETL approach.
As we wrap up our exploration of ETL vs ELT in Big Data, it becomes evident that each approach brings unique advantages and considerations to the table. By carefully weighing the pros and cons of both methodologies, organizations can make informed decisions to optimize their data processing workflows and drive innovation in the ever-evolving realm of Big Data analytics.



{kind=link}