Kicking off with Hadoop Distributed File System (HDFS), this opening paragraph is designed to captivate and engage the readers, setting the tone ahrefs author style that unfolds with each word.
HDFS plays a crucial role in handling large-scale data storage with its unique architecture and features, setting it apart from traditional file systems. Dive deeper into the components, data replication, and file storage of HDFS to understand its inner workings.
Overview of Hadoop Distributed File System (HDFS)

Hadoop Distributed File System (HDFS) is a distributed file system designed to store and manage large volumes of data across clusters of computers. It is a key component of the Apache Hadoop ecosystem and is optimized for handling big data applications.
Analytical dashboards are essential for unlocking data insights that drive business success. These tools provide real-time visibility into key performance indicators, allowing businesses to make proactive decisions based on accurate information. By utilizing analytical dashboards effectively, organizations can optimize operations and stay ahead of the competition. Discover more about Analytical Dashboards Unlocking Data Insights for Business Success.
Key Features of HDFS
- Scalability: HDFS can scale horizontally by adding more commodity hardware to the cluster, allowing it to accommodate petabytes of data.
- Fault Tolerance: HDFS replicates data across multiple nodes in the cluster to ensure that data is not lost in case of hardware failures.
- High Throughput: HDFS is optimized for streaming data access, making it suitable for applications that require high throughput.
- Data Locality: HDFS stores data close to the compute nodes that process it, reducing network traffic and improving performance.
Differences from Traditional File Systems
Unlike traditional file systems that are designed for single machines, HDFS is designed to run on clusters of commodity hardware. This allows HDFS to store and process data across multiple machines, providing scalability and fault tolerance.
Business reporting plays a crucial role in enhancing decision-making through data. By analyzing and presenting key metrics, businesses can gain valuable insights to make informed choices. With the right tools and strategies, organizations can leverage data-driven reports to drive growth and success in today’s competitive market. Learn more about Business reporting Enhancing Decision-Making Through Data.
Architecture of HDFS
HDFS follows a master-slave architecture with two main components: NameNode and DataNode. The NameNode manages the metadata of the file system, while the DataNode stores the actual data blocks. This separation allows for parallel processing and efficient data storage across the cluster.
Data-driven reports are instrumental in making informed decisions based on reliable data. By analyzing trends and patterns, businesses can identify opportunities and mitigate risks effectively. With the right data-driven approach, organizations can streamline processes and drive growth in a dynamic business environment. Explore more about Data-driven reports Making Informed Decisions with Data.
Components of Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) consists of several key components that work together to manage and store data efficiently. These components include the NameNode, DataNode, and Secondary NameNode.
NameNode
The NameNode is the central component of HDFS and serves as the master server that manages the metadata for all the files and directories in the file system. It keeps track of the structure of the file system, including information such as file names, permissions, and the location of data blocks. The NameNode does not store the actual data but acts as a reference point for accessing and managing it.
DataNode
DataNodes, on the other hand, are responsible for storing the actual data in HDFS. They are the worker nodes that manage the storage and retrieval of data blocks. DataNodes receive instructions from the NameNode on where to store data and how to replicate it for fault tolerance. They report back to the NameNode periodically to provide updates on the status of the data blocks they manage.
Secondary NameNode
The Secondary NameNode is not a backup or failover NameNode as the name might suggest. Instead, it assists the primary NameNode in checkpointing its metadata. The Secondary NameNode periodically merges the namespace image with the edit log to create a new checkpoint, which helps reduce the recovery time in case of a failure.
These components work together in a coordinated manner to ensure data reliability and fault tolerance in HDFS. The NameNode maintains the metadata for efficient data access, while the DataNodes store and replicate data blocks across the cluster. The Secondary NameNode helps in maintaining a consistent and up-to-date checkpoint of the metadata. This architecture allows HDFS to handle large amounts of data and provide high availability and fault tolerance for distributed storage systems.
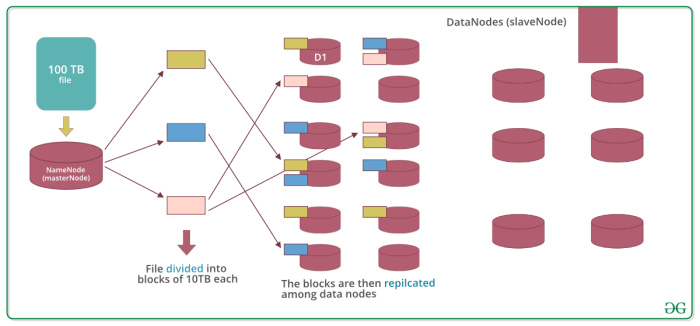
Data Replication in Hadoop Distributed File System: Hadoop Distributed File System (HDFS)

Data replication in HDFS plays a crucial role in ensuring data reliability, fault tolerance, and high availability. By replicating data across multiple nodes, HDFS minimizes the risk of data loss due to hardware failures or network issues.
Replication Factor in HDFS
In HDFS, the replication factor determines how many copies of each data block are stored across different nodes in the cluster. The default replication factor in HDFS is 3, meaning that each data block is replicated three times. This ensures that even if a node fails, the data is still accessible from other replicas.
- Increasing the replication factor improves data durability but also consumes more storage space and network bandwidth.
- Conversely, reducing the replication factor saves storage space and bandwidth but may compromise data durability.
- Administrators can adjust the replication factor based on the specific requirements of their data and workload.
Maintaining Data Integrity through Replication, Hadoop Distributed File System (HDFS)
HDFS maintains data integrity by constantly monitoring the health of nodes and data blocks in the cluster. When a node or data block is found to be faulty or corrupted, HDFS automatically creates new replicas to replace the compromised ones. This self-healing mechanism ensures that the data remains consistent and accessible despite potential failures.
By replicating data and ensuring multiple copies across nodes, HDFS provides fault tolerance and high availability for big data processing applications.
File Storage and Data Access in Hadoop Distributed File System

Files in Hadoop Distributed File System (HDFS) are stored and managed in a distributed manner across a cluster of machines. When a file is uploaded to HDFS, it is broken down into blocks of a fixed size (typically 128 MB or 256 MB). These blocks are then distributed across different nodes in the cluster for storage.
Data Access in HDFS
- For read operations in HDFS, the client first contacts the NameNode to obtain the locations of the blocks that make up the file. The client then directly communicates with the DataNodes that store these blocks to retrieve the data.
- When it comes to write operations, the client again contacts the NameNode to create a new file. The NameNode then determines the DataNodes where the blocks of the file will be stored. The client writes the data directly to these DataNodes.
Advantages of Block-based Storage in HDFS
- Efficient Handling of Large Files: By breaking down files into blocks and distributing them across nodes in the cluster, HDFS can efficiently handle large files that may not fit on a single disk or machine.
- Fault Tolerance: The replication of data blocks across multiple DataNodes ensures fault tolerance. If a DataNode goes down, another replica of the block can be easily accessed from a different node.
- Parallel Processing: With data distributed across multiple nodes, HDFS allows for parallel processing of data, enabling faster read and write operations.
In conclusion, Hadoop Distributed File System (HDFS) stands as a robust solution for managing big data with its efficient data replication, fault tolerance features, and block-based storage advantages. Embrace the power of HDFS for seamless data storage and access in your projects.



{kind=link}