Real-time data processing is a crucial aspect of today’s digital landscape, enabling businesses to make informed decisions at lightning speed. Let’s delve into the world of real-time data processing and explore its significance.
Overview of Real-time Data Processing

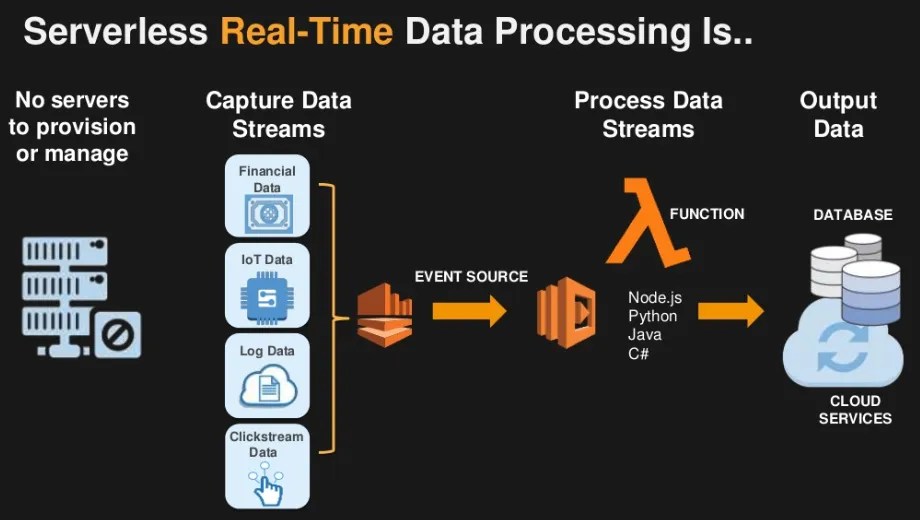
Real-time data processing refers to the method of continuously inputting and analyzing data as soon as it becomes available. This allows organizations to make immediate decisions based on the most up-to-date information.
In today’s digital world, real-time data processing is crucial for businesses to stay competitive and agile. With the rise of big data and the need for instant insights, real-time processing enables companies to react swiftly to changing market conditions, customer preferences, and operational issues.
Importance of Real-time Data Processing
Real-time data processing provides several key advantages, including:
- Swift decision-making: By analyzing data as it comes in, organizations can make informed decisions quickly, leading to better outcomes.
- Improved customer experience: Real-time processing allows businesses to personalize interactions and offer relevant recommendations based on the latest data.
- Enhanced operational efficiency: With real-time insights, companies can optimize processes, detect anomalies, and prevent issues before they escalate.
Examples of Industries Relying on Real-time Data Processing
- Finance: Banks and financial institutions use real-time data processing to detect fraudulent transactions, monitor stock market fluctuations, and provide instant updates to customers.
- Retail: E-commerce companies leverage real-time processing to recommend products, manage inventory levels, and track customer behavior in real-time.
- Transportation: Logistics companies utilize real-time data to optimize routes, track shipments, and respond to changing traffic conditions promptly.
Characteristics of Real-time Data Processing

Real-time data processing refers to the ability to process data immediately after it is generated, allowing for instant analysis and decision-making. This approach has several key characteristics that set it apart from traditional batch processing methods.
Key Characteristics:
- Rapid Processing: Real-time data processing is designed to handle high volumes of data quickly and efficiently, ensuring minimal latency in data analysis.
- Continuous Data Streaming: Data is processed as it is generated, allowing for continuous monitoring and analysis of incoming information.
- Immediate Action: Real-time processing enables immediate responses to events or changes in data, facilitating quick decision-making and problem-solving.
- Scalability: Real-time processing systems are scalable, allowing for flexibility in handling increasing data loads without sacrificing performance.
Challenges Associated:, Real-time data processing
- Complexity: Real-time processing systems can be complex to design and implement, requiring specialized knowledge and expertise.
- Data Quality: Ensuring the accuracy and reliability of real-time data can be challenging, as there is limited time for data validation and cleansing.
- Resource Intensive: Real-time processing can be resource-intensive, requiring significant computational power and storage capacity to handle large volumes of data in real-time.
- Latency: Despite being real-time, there may still be latency issues in processing data, especially in distributed systems or networks with high traffic.
Technologies Used:
- Apache Kafka: A distributed streaming platform that is commonly used for building real-time data pipelines and streaming applications.
- Apache Storm: A real-time computation system that processes large streams of data in real-time, enabling low-latency processing.
- Spark Streaming: An extension of the Apache Spark platform that allows for real-time processing of data streams, supporting complex analytics and machine learning algorithms.
- Amazon Kinesis: A platform for real-time data streaming and processing, providing tools for capturing, processing, and analyzing streaming data at scale.
Architectures for Real-time Data Processing
Real-time data processing involves various architectures that enable the processing of data in real-time to derive insights and make decisions promptly.
Batch Processing vs Real-time Processing
Batch processing involves processing data in large volumes at scheduled intervals, while real-time processing deals with data as soon as it is generated. Batch processing is suitable for non-time-sensitive tasks, while real-time processing is crucial for time-sensitive applications.
- Batch processing:
- Works with large volumes of data
- Processes data at scheduled intervals
- Suitable for non-time-sensitive tasks
- Real-time processing:
- Handles data as it is generated
- Processes data immediately
- Essential for time-sensitive applications
Real-time processing is crucial for applications where immediate decisions need to be made based on the most current data available.
Stream Processing in Real-time Data Processing Architectures
Stream processing is a key component of real-time data processing architectures, enabling the processing of continuous streams of data and generating insights in real-time.
- Stream processing:
- Handles continuous streams of data
- Processes data in real-time
- Enables real-time analytics and decision-making
By incorporating stream processing into real-time data processing architectures, organizations can react quickly to changing data and make informed decisions promptly.
Tools and Technologies for Real-time Data Processing

Real-time data processing requires the use of specialized tools and technologies to handle data streams efficiently, ensuring timely insights and decision-making. Let’s explore some popular tools and technologies used in real-time data processing and how they manage data in real-time.
Apache Kafka
Apache Kafka is a distributed streaming platform that is widely used for real-time data processing. It provides a high-throughput, fault-tolerant, and scalable solution for handling data streams. Kafka allows data to be processed in real-time by enabling the seamless transfer of data between systems and applications through its messaging system.
Apache Spark
Apache Spark is another popular tool for real-time data processing that offers fast and general-purpose cluster computing capabilities. Spark Streaming, a component of Apache Spark, enables real-time processing of streaming data, making it suitable for applications that require low-latency processing of data streams.
AWS Kinesis
Amazon Web Services (AWS) Kinesis is a cloud-based platform that provides services for real-time data processing. AWS Kinesis allows users to collect, process, and analyze streaming data in real-time, offering scalability and flexibility for handling large volumes of data streams.
Apache Flink
Apache Flink is an open-source stream processing framework that supports event-driven applications for real-time data processing. Flink provides capabilities for high-throughput, low-latency processing of data streams, making it suitable for applications that require real-time analytics and monitoring.
Redis
Redis is an in-memory data structure store that is commonly used for real-time data processing. With its high-performance and low-latency data access, Redis is ideal for applications that require real-time data processing and caching of frequently accessed data.
Scalability and Performance Considerations
When selecting tools and technologies for real-time data processing, scalability and performance considerations are crucial. It is essential to choose tools that can handle increasing data volumes and processing loads efficiently, ensuring that real-time insights are delivered promptly without compromising performance.
In conclusion, real-time data processing revolutionizes how businesses operate in the digital age, providing instantaneous access to critical insights. Embracing this technology can pave the way for greater efficiency and competitiveness in the market.
When it comes to managing large datasets, data partitioning techniques play a crucial role in optimizing storage and retrieval processes. By dividing data into smaller partitions, organizations can improve query performance and enhance data processing efficiency.
For businesses looking to store and manage their data in the cloud, Google Cloud Storage offers a reliable and scalable solution. With features like multi-regional storage and strong consistency, Google Cloud Storage ensures data durability and accessibility.
Deploying a robust data warehouse technology is essential for organizations to centralize and analyze data from various sources. By implementing data warehousing solutions, businesses can gain valuable insights and make informed decisions based on data-driven analytics.



{kind=link}