Snowflake data warehouse sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail and brimming with originality from the outset. The innovative approach of Snowflake in managing data in the cloud has reshaped the landscape of data warehousing, making it a topic of great interest and importance in today’s digital age.
As we delve deeper into the intricacies of Snowflake data warehouse, a world of efficiency, scalability, and security unfolds before us, showcasing the remarkable capabilities that set Snowflake apart from traditional data warehousing solutions.
Overview of Snowflake Data Warehouse

Snowflake is a cloud-based data warehousing solution that allows businesses to store and analyze large amounts of data in a scalable and cost-effective manner. Unlike traditional data warehousing solutions, Snowflake is built for the cloud, offering flexibility and ease of use for organizations of all sizes.
Key Features of Snowflake
- Separation of Storage and Compute: Snowflake’s architecture separates storage and compute resources, allowing users to scale each independently based on their needs.
- Automatic Scaling: Snowflake automatically adjusts resources to match workload demands, ensuring optimal performance without manual intervention.
- Zero Copy Cloning: Users can create instant and cost-effective copies of data without duplicating storage, enabling efficient data sharing and testing.
- Data Sharing: Snowflake enables secure data sharing across organizations, making collaboration and analytics easier and more streamlined.
Data Storage and Processing in the Cloud
Snowflake stores data in multiple formats for efficient processing, utilizing a unique architecture that minimizes data duplication and optimizes query performance. By leveraging the power of the cloud, Snowflake offers unlimited scalability and flexibility, allowing businesses to adapt to changing data requirements seamlessly.
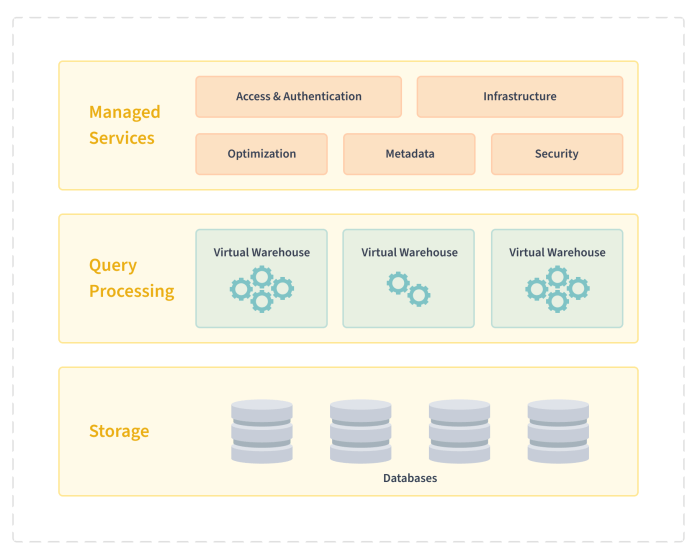
Architecture of Snowflake Data Warehouse

Snowflake Data Warehouse is built on a unique architecture that separates storage and compute resources, providing flexibility, scalability, and performance. Let’s delve into the layers of Snowflake’s architecture and explore the role of virtual warehouses in this innovative platform.
Layers of Snowflake Architecture, Snowflake data warehouse
Snowflake’s architecture consists of three main layers: the storage layer, the compute layer, and the services layer.
- The storage layer is responsible for storing all the data in Snowflake. It utilizes cloud storage, such as Amazon S3 or Azure Blob Storage, to store structured and semi-structured data in a columnar format.
- The compute layer processes queries and performs computations on the data stored in the storage layer. It is where virtual warehouses come into play.
- The services layer acts as the brain of Snowflake, managing metadata, query optimization, security, and other essential functions.
Role of Virtual Warehouses
Virtual warehouses in Snowflake are clusters of compute resources that can be independently scaled up or down based on workload requirements. They allow users to allocate the necessary compute power for running queries without affecting the underlying storage.
Virtual warehouses enable users to run multiple workloads concurrently, providing isolation and optimal performance for each workload.
Separation of Storage and Compute
Snowflake’s unique architecture separates storage and compute resources, allowing users to scale each independently. This separation eliminates the need to provision and manage compute resources, resulting in cost savings and improved performance.
- Storage costs are based on the amount of data stored, while compute costs are based on the amount of compute resources used, providing a flexible and cost-effective pricing model.
- By separating storage and compute, Snowflake ensures that compute resources can be scaled up or down dynamically, providing on-demand performance without any manual intervention.
Data Loading and Unloading in Snowflake

Data loading and unloading are crucial processes in Snowflake data warehouse that involve efficiently transferring data in and out of the platform. Let’s delve into the details of how these operations are carried out.
Data Loading Process
- Data loading into Snowflake involves various methods such as bulk loading, continuous data ingestion, and using Snowpipe for real-time data loading.
- Users can leverage Snowflake’s COPY command to load data from files stored in cloud storage platforms like Amazon S3, Azure Blob Storage, or Google Cloud Storage.
- Additionally, Snowflake supports direct data ingestion from streaming platforms like Kafka for real-time data processing.
Data Unloading Process
- Snowflake allows users to unload data for export using the COPY INTO command, which exports data from Snowflake tables to files in cloud storage.
- Users can specify various file formats like CSV, JSON, Parquet, or Avro for unloading data based on their requirements.
- The unloaded data can then be downloaded or further processed outside of Snowflake for analysis or sharing with external systems.
Best Practices for Efficient Data Loading and Unloading
- Optimize data loading by parallelizing the process using Snowflake’s clustering keys to distribute data evenly across nodes for faster loading times.
- Utilize Snowflake’s auto-scaling capabilities to automatically adjust resources based on the workload, ensuring efficient data loading and unloading performance.
- Regularly monitor and optimize data loading and unloading processes to identify bottlenecks and improve overall data transfer efficiency.
Querying and Performance in Snowflake
When it comes to querying and performance in Snowflake, understanding how queries are processed and optimizing them for improved performance are crucial aspects. Let’s delve into the details below.
Query Processing in Snowflake
In Snowflake, queries are processed using a unique architecture that separates storage and compute resources. When a query is submitted, Snowflake optimizes it by breaking it down into smaller tasks that can be processed in parallel across multiple compute nodes. This distributed processing approach allows for fast and efficient query execution.
Optimization Techniques for Improved Query Performance
To enhance query performance in Snowflake, consider the following optimization techniques:
- Use appropriate clustering keys to organize data efficiently.
- Create materialized views to precompute and store query results.
- Utilize query profiling to identify and address performance bottlenecks.
- Monitor and adjust warehouse size based on workload requirements.
Comparison with Traditional Data Warehousing Systems
When compared to traditional data warehousing systems, Snowflake offers significant advantages in terms of performance. Its ability to scale dynamically and handle massive workloads without manual tuning sets it apart from on-premises solutions. Additionally, Snowflake’s pay-as-you-go pricing model ensures cost-effectiveness while delivering high performance for analytical workloads.
Security and Governance in Snowflake
Snowflake offers robust security features to ensure the protection of data within the data warehouse. This includes encryption options, role-based access control, and compliance with various data governance regulations.
Security Features Offered by Snowflake
Snowflake provides end-to-end encryption of data, both at rest and in transit, using strong encryption standards. This ensures that data is secure throughout the entire data lifecycle. Additionally, Snowflake allows for the implementation of multi-factor authentication to enhance user security.
Data Governance and Compliance in Snowflake
Snowflake helps organizations maintain data governance and compliance by providing audit logging and tracking capabilities. This allows users to monitor who accessed the data, made changes, and ensures compliance with regulations such as GDPR and HIPAA. Snowflake also offers data masking features to protect sensitive information.
Role-Based Access Control and Encryption Options
Role-based access control in Snowflake enables organizations to define granular permissions for users based on their roles and responsibilities. This ensures that users only have access to the data they need to perform their tasks. Additionally, Snowflake provides various encryption options, including column-level encryption, to further enhance data security.
In conclusion, Snowflake data warehouse emerges as a game-changer in the realm of cloud data management, offering a powerful and efficient solution for organizations looking to optimize their data operations. With its robust architecture, advanced features, and unwavering focus on security and compliance, Snowflake stands as a beacon of innovation in the ever-evolving world of technology.
When it comes to managing large volumes of data, businesses rely on data warehouse technology to store, analyze, and retrieve information efficiently. This technology enables organizations to consolidate data from different sources into a single repository for easy access and decision-making.
For companies looking to scale their data storage capabilities, implementing scalable data storage solutions is crucial. This allows businesses to expand their data infrastructure seamlessly as their needs grow, ensuring optimal performance and flexibility.
Managing large datasets across distributed systems can be challenging without the right tools. The Hadoop Distributed File System (HDFS) offers a scalable solution for storing and processing big data efficiently, making it a popular choice among enterprises.



{kind=link}