Distributed database systems take the spotlight in this exploration, offering a glimpse into a realm where data management is optimized for superior results and seamless operations.
Delve into the intricacies and advantages of distributed database systems as we uncover the key components shaping the landscape of modern data architecture.
Overview of Distributed Database Systems

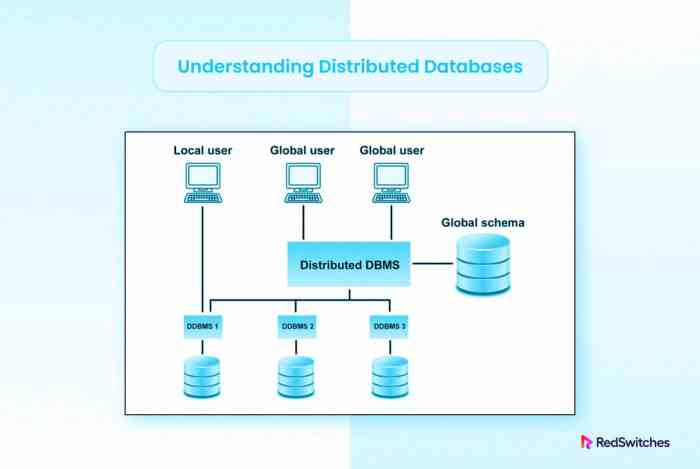
Distributed database systems refer to a network of multiple databases located in different physical locations but connected through a data communication network. These databases work together to provide a unified view to the users, allowing them to access and manipulate data as if it were all stored in a single location.
Examples of Industries/Applications
- Finance: Banks and financial institutions use distributed database systems to securely store and manage customer information, transactions, and financial data across multiple branches.
- Retail: E-commerce platforms utilize distributed databases to manage inventory, customer orders, and product information across various warehouses and locations.
- Telecommunications: Telecom companies rely on distributed database systems to handle vast amounts of customer data, network configurations, and call records efficiently.
Benefits of Distributed Database Systems
- Improved Performance: Distributing data across multiple nodes reduces the load on individual servers, leading to faster query processing and improved response times.
- Enhanced Availability: Redundant data storage and replication ensure high availability even if one node fails, preventing downtime and data loss.
- Scalability: Distributed database systems can easily scale horizontally by adding more nodes to the network, accommodating growing data storage and processing needs without significant disruptions.
- Geographical Flexibility: With data distributed across multiple locations, distributed database systems provide flexibility for organizations operating in different regions or countries, ensuring compliance with local regulations.
Architecture of Distributed Database Systems
Distributed database systems are designed to store and manage data across multiple interconnected nodes or locations. This architecture allows for better scalability, fault tolerance, and improved performance compared to traditional centralized database systems.
Key Components of Distributed Database Systems:
1. Data Fragmentation and Distribution: Data is divided into smaller fragments and distributed across different nodes in the network. This allows for parallel processing and faster access to data.
2. Replication: Data replication involves creating and maintaining multiple copies of data across different nodes. This ensures data availability and fault tolerance in case of node failures.
3. Distributed Query Processing: Queries are processed in a distributed manner, where each node can execute part of the query and combine results to provide the final output.
4. Transaction Management: Distributed database systems need to ensure the ACID properties (Atomicity, Consistency, Isolation, Durability) for transactions spanning multiple nodes.
5. Distributed Metadata Management: Metadata, such as data dictionary and schema information, needs to be managed in a distributed manner to maintain data consistency and integrity.
Comparison with Centralized Database Systems:
– In centralized database systems, all data is stored in a single location, while distributed systems store data across multiple nodes.
– Centralized systems have a single point of failure, whereas distributed systems are more fault-tolerant due to data replication.
– Scalability is limited in centralized systems, as adding more resources to a single server can only go so far. Distributed systems can scale horizontally by adding more nodes to the network.
Scalability and Fault Tolerance
- Data fragmentation allows distributed systems to scale efficiently by adding more nodes to handle increased data volume.
- Replication ensures data availability and fault tolerance, reducing the risk of data loss in case of node failures.
Data Distribution Strategies

When dealing with distributed database systems, data distribution strategies play a crucial role in ensuring efficient data access and management across multiple nodes. Various strategies are employed to distribute data effectively, depending on the specific requirements of the system.
Horizontal Data Partitioning
Horizontal data partitioning involves dividing a table’s rows into multiple partitions based on a specific attribute. Each partition is stored on a separate node, allowing for parallel processing and improved query performance. This strategy is suitable for scenarios where the workload can be evenly distributed among nodes, such as in e-commerce platforms with customer data partitioned by geographical regions.
Vertical Data Partitioning
Vertical data partitioning, on the other hand, involves splitting a table’s columns into separate partitions stored on different nodes. This strategy is beneficial when certain columns are accessed more frequently than others, allowing for optimized data retrieval. For example, in a healthcare system, patient demographics data could be stored separately from medical records to improve query speed.
Replication
Replication involves creating and maintaining copies of data across multiple nodes to ensure high availability and fault tolerance. This strategy is commonly used in scenarios where data needs to be accessed quickly and consistently, such as in real-time analytics applications or financial systems requiring redundancy for critical information.
Sharding
Sharding is a strategy that involves partitioning data based on a specific key or attribute and distributing these shards across different nodes. This approach is suitable for systems with a large volume of data that can be logically divided, such as social media platforms partitioning user data based on user IDs to scale horizontally and handle increased user traffic.
Factors Influencing Data Distribution Strategy
– System scalability requirements
– Query performance needs
– Data access patterns
– Network latency considerations
– Fault tolerance and redundancy requirements
Replication and Partitioning in Distributed Databases

Data replication and partitioning are two key concepts in distributed databases that play a crucial role in improving performance and availability.
Looking into NoSQL databases , companies can benefit from flexible data models and horizontal scaling. With various types like key-value, document, and column-family stores, NoSQL databases cater to different data management needs.
Data Replication
Data replication involves creating and maintaining copies of data across multiple nodes in a distributed database system. This ensures that data is available locally on different nodes, reducing the latency for accessing data and enhancing fault tolerance. However, data replication can lead to issues such as inconsistency if updates are not synchronized properly across all replicas.
When it comes to Cassandra data management , businesses need to ensure efficient handling of big data. This NoSQL database offers high availability and scalability, making it a popular choice for organizations dealing with large volumes of data.
Data Partitioning
Data partitioning, on the other hand, involves dividing the database into smaller subsets or partitions that are distributed across different nodes. This allows for parallel processing of queries and distributes the workload evenly across the nodes. However, data partitioning can lead to data skew if the partitions are not evenly distributed or if there are hotspots in the data that result in uneven access patterns.
When it comes to Cassandra data management, businesses are turning to innovative solutions to handle the massive amounts of data generated daily. With the rise of NoSQL databases, such as NoSQL databases , companies are able to store and retrieve data in a more efficient and scalable manner. By implementing advanced Data lake solutions, organizations can centralize their data storage and analytics, leading to improved decision-making processes.
Advantages and Disadvantages
- Advantages of Data Replication: Improved fault tolerance, reduced latency, increased availability.
- Disadvantages of Data Replication: Potential for data inconsistency, increased storage requirements.
- Advantages of Data Partitioning: Enhanced parallel processing, even distribution of workload.
- Disadvantages of Data Partitioning: Data skew, potential hotspots, complex data distribution strategies.
Challenges in Maintaining Consistency
One of the major challenges in distributed databases with data replication is maintaining consistency across all replicas. Ensuring that updates are propagated to all replicas in a timely manner and handling conflicts that may arise due to concurrent updates are critical issues. Techniques such as quorum-based protocols, versioning, and conflict resolution mechanisms are used to address these challenges and maintain data consistency in distributed systems.
Consistency and Concurrency Control
Consistency and concurrency control are crucial aspects of distributed database systems to ensure data integrity and reliability. In a distributed environment where data is spread across multiple nodes, maintaining consistency and controlling concurrent access to data becomes challenging but essential for the system’s overall performance and reliability.
Techniques for Ensuring Data Consistency, Distributed database systems
- Two-Phase Commit Protocol: This protocol ensures that all nodes agree to commit or rollback a transaction, maintaining consistency across the distributed system.
- Timestamp Ordering: Assigning timestamps to transactions and using them to order the execution of concurrent transactions helps maintain consistency in a distributed environment.
- Quorum Consistency: By requiring a certain number of nodes to agree on a transaction before committing, quorum consistency helps ensure data consistency in distributed databases.
Role of Distributed Transactions
- Distributed transactions play a crucial role in maintaining data integrity and isolation in a distributed database system.
- They ensure that a group of operations across multiple nodes either commit or rollback together, maintaining consistency and preventing data corruption.
- Isolation levels in distributed transactions help control concurrent access to data, preventing conflicts and ensuring each transaction’s atomicity and durability.
Scalability and Performance: Distributed Database Systems
Distributed database systems offer significant advantages in terms of scalability and performance compared to centralized databases. By distributing data across multiple nodes, these systems can handle a large volume of data and a high number of transactions efficiently.
Enhanced Scalability
One of the key benefits of distributed database systems is their ability to scale horizontally by adding more nodes to the system. This allows for increased storage capacity and processing power as the data volume grows. In contrast, centralized databases may face limitations in scalability due to hardware constraints.
Impact on Performance
The distributed architecture of database systems can have a significant impact on performance. By distributing data and workload across multiple nodes, operations can be performed in parallel, leading to faster query processing and reduced response times. However, network latency and communication overhead between nodes can also affect performance.
Optimizing Performance Strategies
- Use of data partitioning: Partitioning data based on certain criteria can improve performance by reducing the amount of data that needs to be processed for each query.
- Replication: Replicating data across multiple nodes can enhance read performance by allowing queries to be served from the nearest replica.
- Caching: Implementing caching mechanisms can help reduce the frequency of data access from disk, improving overall performance.
- Load balancing: Distributing workload evenly across nodes can prevent bottlenecks and optimize resource utilization for better performance.
In conclusion, the journey through distributed database systems unveils a realm of enhanced scalability, optimized performance, and meticulous data management strategies that pave the way for future innovations in the digital landscape.
For those exploring Data lake solutions , integrating multiple data sources into a centralized repository is key. Data lakes enable organizations to analyze and derive insights from diverse data sets, leading to informed decision-making.



{kind=link}