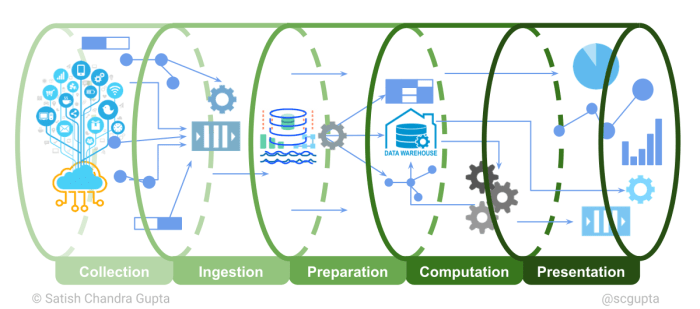
Big Data processing pipelines revolutionize the way data is handled, ensuring streamlined and efficient processing for various industries. From data ingestion to storage, this comprehensive guide explores the key components and technologies that power these pipelines.
Delve into the world of Big Data processing pipelines and discover how organizations can leverage them to unlock valuable insights and drive innovation.
Overview of Big Data processing pipelines
Big Data processing pipelines refer to a series of data processing tasks that are designed to ingest, process, transform, and analyze large volumes of data efficiently. These pipelines are crucial for organizations that deal with massive amounts of data and need to derive valuable insights from it in a timely manner.
Industries and Use Cases
- Finance: Big Data processing pipelines are essential in the finance industry for fraud detection, risk analysis, and algorithmic trading.
- Healthcare: Healthcare organizations use Big Data pipelines for patient data analysis, personalized medicine, and disease outbreak detection.
- Retail: Retail companies utilize Big Data pipelines for customer segmentation, demand forecasting, and recommendation systems.
Benefits of Efficient Big Data Processing Pipelines
- Real-time Insights: Efficient pipelines enable organizations to derive real-time insights from large volumes of data, allowing for quick decision-making.
- Scalability: Big Data pipelines can scale to process petabytes of data, ensuring that organizations can handle growing data volumes.
- Cost-effectiveness: By automating data processing tasks and optimizing resource utilization, efficient pipelines help reduce operational costs.
Components of Big Data processing pipelines

Data processing pipelines rely on several key components to efficiently handle large volumes of data. These components work together to ingest, process, store, and retrieve data in a structured and organized manner.
Data Ingestion
Data ingestion is the first step in a Big Data processing pipeline, where raw data is collected from various sources such as databases, sensors, applications, or external feeds. This data is then transferred to the processing system for further analysis. The role of data ingestion is crucial as it ensures that the pipeline receives a continuous flow of data to work with.
Data Processing and Transformation
Once the data is ingested, it needs to be processed and transformed into a usable format. Data processing involves cleaning, filtering, aggregating, and analyzing the raw data to derive valuable insights. Transformation steps may include data normalization, enrichment, and feature engineering to prepare the data for downstream analysis. Efficient data processing and transformation are essential for accurate and meaningful results.
Data Storage and Retrieval, Big Data processing pipelines
Data storage mechanisms play a vital role in Big Data processing pipelines as they determine how data is stored, accessed, and retrieved. Storage solutions such as databases, data lakes, and data warehouses are used to store processed data for future use. Data retrieval mechanisms ensure that the processed data can be accessed quickly and efficiently when needed for analysis or reporting purposes. Choosing the right storage and retrieval mechanisms is crucial for the overall performance and scalability of the pipeline.
Technologies used in Big Data processing pipelines

Big Data processing pipelines rely on a variety of technologies to handle the massive volume, velocity, and variety of data generated. These technologies play a crucial role in enabling organizations to extract valuable insights from their data efficiently.
Apache Hadoop
Apache Hadoop is a widely used open-source framework for distributed storage and processing of large datasets. It consists of the Hadoop Distributed File System (HDFS) for storage and MapReduce for processing. Hadoop’s distributed nature allows it to scale horizontally, making it suitable for handling Big Data workloads.
Apache Spark
Apache Spark is another popular open-source framework that provides a fast and general-purpose engine for large-scale data processing. Spark’s in-memory processing capabilities make it ideal for real-time data processing tasks, such as stream processing and machine learning. It offers a more flexible and efficient alternative to MapReduce, especially for iterative algorithms.
Apache Kafka
Apache Kafka is a distributed streaming platform that is commonly used for building real-time data pipelines and streaming applications. It provides high-throughput, fault tolerance, and scalability, making it a critical component in Big Data processing pipelines for handling continuous streams of data.
Apache Flink
Apache Flink is a powerful stream processing framework that offers low-latency processing and high-throughput. It supports event-time processing, state management, and fault tolerance, making it suitable for complex event processing and real-time analytics in Big Data applications.
AWS Services
Amazon Web Services (AWS) offers a range of cloud-based services that are commonly used in Big Data processing pipelines. Services like Amazon EMR (Elastic MapReduce), Amazon Kinesis, and Amazon Redshift provide scalable and cost-effective solutions for storing, processing, and analyzing large volumes of data in the cloud.
Challenges in building and maintaining Big Data processing pipelines

Building and maintaining Big Data processing pipelines come with their own set of challenges that need to be addressed for a successful implementation. These challenges range from scalability issues to ensuring data quality and reliability throughout the pipeline. Additionally, monitoring and troubleshooting are essential for identifying and resolving issues that may arise during the processing of large volumes of data.
Scalability Challenges
Managing large volumes of data in Big Data processing pipelines can lead to scalability challenges. As the amount of data grows, the pipeline must be able to handle the increased load efficiently. This requires careful planning and implementation to ensure that the pipeline can scale horizontally to accommodate the growth in data volume. Without proper scalability measures in place, the pipeline may become overwhelmed, leading to bottlenecks and performance issues.
Data Quality and Reliability
Maintaining data quality and reliability is crucial for the effectiveness of Big Data processing pipelines. Inaccurate or incomplete data can lead to errors in processing, affecting the overall output and decision-making based on the processed data. It is essential to implement data validation and cleansing processes to ensure that the data entering the pipeline is accurate and reliable. Additionally, establishing data governance practices can help maintain data quality and integrity throughout the pipeline.
Monitoring and Troubleshooting Strategies
Monitoring and troubleshooting are vital components of maintaining efficient Big Data processing pipelines. By implementing robust monitoring tools and practices, organizations can proactively identify issues such as bottlenecks, failures, or performance degradation in the pipeline. This allows for timely intervention and resolution to minimize downtime and ensure the continuous flow of data. Troubleshooting strategies involve identifying the root cause of issues, implementing fixes, and optimizing the pipeline to prevent similar problems in the future.
In conclusion, Big Data processing pipelines play a crucial role in today’s data-driven world, offering organizations the ability to manage and analyze massive amounts of data effectively. Embracing these pipelines can lead to improved decision-making and operational efficiency, making them a cornerstone of modern data processing strategies.
Cloud-native data management is essential for businesses looking to harness the power of cloud technology for their data storage and processing needs. By adopting a cloud-native approach, organizations can optimize their data management strategies to be more efficient, scalable, and cost-effective. With the help of tools like Kubernetes and Docker, companies can easily deploy and manage their data in the cloud, ensuring seamless operations and improved performance.
To learn more about cloud-native data management, check out this informative article on Cloud-native data management.
Apache Flink is a powerful open-source stream processing framework that enables real-time analytics and data processing at scale. With its advanced capabilities for event time processing, state management, and fault tolerance, Apache Flink is a popular choice for organizations seeking to build robust and reliable data pipelines. By leveraging Apache Flink, businesses can achieve low-latency data processing, high throughput, and accurate results for their analytics workloads.
If you’re interested in learning more about Apache Flink, be sure to check out this comprehensive guide on Apache Flink.
Data archiving solutions play a crucial role in helping organizations effectively manage and store their data for long-term retention and compliance purposes. By implementing data archiving solutions, businesses can reduce storage costs, improve data accessibility, and ensure regulatory compliance. With a variety of options available in the market, such as cloud-based archiving services and on-premises solutions, companies can choose the best fit for their specific needs.
To explore more about data archiving solutions and their benefits, take a look at this insightful article on Data archiving solutions.



{kind=link}